![[CS231n] Lecture 1 | Introduction to Convolutional Neural Networks for Visual Recognition](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FAzVyn%2FbtraBdjmRWZ%2FNz7SXmPSrfDIPRFryi22Uk%2Fimg.png)
해당 강의노트는 Stanford University CS231n Spring 2017 강의를 기반으로 작성했음을 밝힙니다.
통계에 따르면 인터넷 트래픽 중에서 80%는 비디오 데이터입니다. 인터넷에서 대부분의 데이터가 시각 데이터라는 점을 알 수 있습니다. 많은 양의 시각 데이터를 이해하고 분석하기 위해 자동으로 이를 분석하는 알고리즘을 개발하려고 노력하는 분야가 컴퓨터 비전(CV)입니다.
컴퓨터 비전의 역사
1강에서는 컴퓨터 비전의 역사에 대해 중점적으로 설명합니다.
포유류의 시각 처리 메커니즘
1950, 60년대에 전기생리학을 이용한 Hubel과 Wisel의 연구가 있습니다. 연구 주제는 포유류의 시각적 처리 메커니즘은 무엇인가 였습니다. 고양이의 두뇌에서 일차 시각 피질이 어떤 자극에 따라 뉴런들이 어떻게 반응하는지 살펴봤습니다. 그 결과 몇몇 세포들이 엣지에 따라 반응한다는 사실을 알 수 있었습니다. 처음에는 edges들에 대해 반응하고 이후 실제 세상을 제대로 인지할 수 있을 때까지 정보가 통로를 거쳐가면서 보다 복잡해집니다.
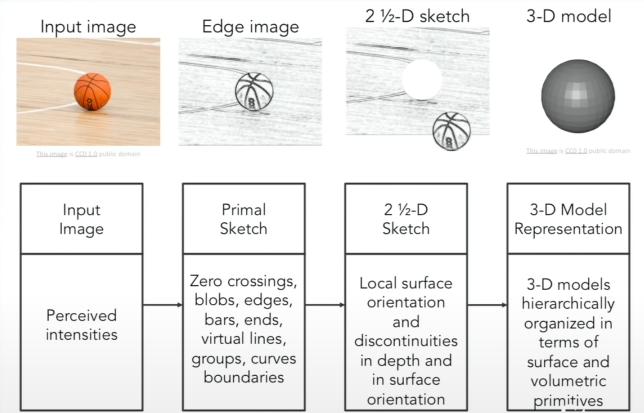
이미지의 최종적인 Full 3D 표현
비전 과학자인 David Marr가 쓴 저서에서 나온 내용입니다. 눈에 입력된 이미지를 최종적인 full 3D 표현으로 만들기 위해선 3가지의 단계를 거쳐야한다고 주장했습니다. 첫 단계는 Primal Sketch입니다. Hubel과 Wisel의 고양이 실험에서 확인한 시각 처리의 초기 단계는 경계와 같은 단순한 구조와 밀접한 관계가 있다는 점에서 착안했습니다. 해당 단계는 edges, bars, ends, virtual lines, curves, boundaries를 표현합니다. 2 1/2 D sketch 단계에서는 시각 장면을 surface, depth, layer, 불연속 점 등과 같은 정보로 종합합니다. 이러한 표현들을 모아 3D model representation 단계에서는 surface and volumetric primives의 형태로 계층적으로 조직화된 최종적인 3D 모델을 만듭니다.
Genralized Cylinder와 Pictorial Structure
Stanford와 SRI에서는 서로 비슷한 아이디어로 genralized cylinder와 pictorial structure를 제안합니다. 모든 객체는 단순한 기하학적 형태로 표현할 수 있다라는 기본 개념에서 출발합니다. Generalizerd Cylinder는 사람을 원통 모양으로 Pictorial Structure는 주요 부위, 관절로 표현한 것입니다. 두 방법 모두 복잡한 객체인 사람을 단순한 모양과 기하하적인 구성을 이용해서 표현했습니다. 이러한 시도는 이후, 어떤 사물을 인식하기 위해 어떻게 단순한 구조로 재구성할지에 대해 연구하게 합니다.

객체 분할(Image Segmentaion)
객체 인식은 80년대까지 활발히 연구는 이뤄졌지만, 진보한 결과를 내진 못했습니다. 그러면서 등장한 개념이 객체 분할(Image Segmentation)입니다. 이미지의 각 픽셀을 의미있는 방향으로 군집화하는 것입니다. 객체 분할을 하기 위해 그래프 이론을 도입했고, Face Detection에서 이를 활용할 수 있었습니다.
통계적 기계학습
2000년대에는 기계학습 중에서도 통계적 기계학습이 붐이었습니다. SVM(Support Vector Machine), Boosting, Graphical models, 초기 Neural Network 등이 활발히 연구되었습니다.
특징 기반 객체인식 알고리즘
2010년도까지는 David Lowe의 SIFT feature와 같은 특징기반 객체인식 알고리즘이 큰 연구 흐름이이었습니다. SIFT feature는 다른 영상 속에 같은 객체더라도 카메라 앵글의 변화, 겹침, 조도 변화, 객체 자체의 변화 등 때문에 같은 객체로 매칭하기 어렵다는 문제를 해결할 수 있는 실마리를 찾아냈습니다. 이러한 다양한 변화가 있더라도 객체의 특징 중에 변화에 강인한 불변한 특징을 가지는 특징이 있다는 점을 발견했습니다. 이후 Spatial Pyramid Matching처럼 장면 전체에서 특징들을 단서로 활용하고, SVM을 적용하는 시도 등이 나타났습니다.

Benchmark Dataset
객체 인식이 CV의 주요 태스크였기 때문에 기술 평가에 대한 측정을 위해 Benchmark Dataset을 구축하기 시작했습니다. PASCAL Visual Object Challenge(VOC), ImageNet처럼 클래스당 수천 수만 개의 이미지가 있는 데이터셋들이 구축됐습니다.
세상 모든 객체 인식과 과적합(Overfit)
21세기에는 CV에서 2가지 Motivation이 있었습니다. 먼저, Princeton과 Stanfode에서 던진, 모든 객체를 인식할 수 있는가? 입니다. 그리고, 시각 데이터는 너무 복잡하기 때문에 Graphical Model, SVM, AdaBoost 알고리즘들을 활용했을 때 나타나는 Overfit 문제를 해결하고자 했습니다. ImageNet을 구축한 팀에서는 ILSVRC라는 국제 규모의 이미지 분류 대회를 주최합니다. 2012년부터는 오류율이 사람보다 낮아지기 시작합니다! 해당 알고리즘이 바로 CNN(Convolution Neural Network) 모델입니다.
CS231n에서 배울 내용
Object Detection
Image Classification은 주어진 사진이 어느 클래스에 속하는지 구분하는 것이지만, Object Detection은 해당하는 객체의 위치를 정확히 파악하여 네모박스를 그릴 수 있어야합니다.
Image captioning
이미지가 입력으로 주어지면, 이미지를 묘사하는 적절한 문장을 생성하는 태스크입니다.
CNN(Convolution Neural Network)

Convnet이라고도 불리는 CNN 모델은 ImageNet Challenge의 우승자들의 모델을 보면서 여러 접근 방식들에 대해 살펴볼 수 있습니다. 먼저 2011년에는 이미지 특징을 뽑고 로컬 불변 특징들을 계산한 후에 Pooling을 거친 후에 Linear SVM을 사용합니다. 해당 알고리즘은 계층적이고, edges를 뽑을 때 불변하는 특징들에 주목한다는 특징이 있습니다.

2012년에는 7 Layer CNN 모델이 등장했습니다. AlexNet 또는 Supervision이라고 하는 CNN 모델이 등장 후, 매년 CNN 모델들이 수상자가 되었습니다. AlexNet은 7 Layer 또는 8 Layer라고도 불리는데, Layer를 세는 방식에 따라 달라집니다.
점점 네트워크가 깊어지면서 Google의 GoogLeNet, Oxford의 VGGNet, MSRA의 Residual Network 등이 등장합니다. Residual Networks는 Layer가 152개에 달합니다. 그러나 GPU 메모리가 이를 감당할 수 없기 때문에 한없이 Layer를 깊이 가져갈 순 없습니다.