![[Dacon] 인공지능 비트 트레이더 경진대회 시즌 1 참여 후기](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FZFACn%2Fbtq2kqJnv7f%2FX1gXU7RUOulUfTckhpLyXk%2Fimg.png)
인공지능 비트 트레이더 경진대회
출처 : DACON - Data Science Competition
dacon.io
시즌 1 | 연간데이콘 | 금융 | 시계열 | 암호화폐 | 모의투자
팀 구성
AIFFEL 대전에서 IY님, MJ님, LS님, 나 이렇게 4명이서 참여했습니다. AIFFEL 컨텐츠를 공부하기 위해 뭉친 스터디에서 데이터 경진대회에 도전해보기 위해 4명이 뭉쳤습니다. MJ님께서 사다리타기 운명적으로 팀장을 하게 되었습니다. 최고의 팀장 🎈
팀 진행
어떻게 업무 분담하는 것이 좋을까?
이전에도 모든 팀원들이 노베이스인 상태에서 공모전을 참여했을 때 겪었던 어려움이 업무 분담이었습니다. 주변에 잘 모를 때 어떻게 팀을 진행하는게 좋은지 고민이 많이 됐습니다. 이전에 공모전 참여한 팀원에게 조언을 구했는데 네이버에서 들은 특강을 언급하면서 다같이 부족할땐 다같이 진행하는게 좋다고 말씀해주셨습니다. 그래서 업무를 쪼개기 보다는 같이 해보는 걸 스리슬쩍 제안했습니다.
팀원들과 업무 분담에 대해 얘기했을 때도 의견이 나뉘는 부분이 있어서 둘둘씩 나눠서 진행했습니다. 사실 처음이다보니 업무 분담이 명확히 이뤄지지는 않았습니다. MJ님은 새로운 모델을 구현하고 학습해보기, IY님은 베이스라인을 조합해서 돌려보기, 나는 데이터 시각화하고 분석해보기, LS님은 우리의 히든 카드를 준비하기(시즌2에도 참여할 예정이니까 대외비!)로 업무를 나눴으나, Basline에서 제공된 시각화 이상으로 각각의 sample만 시각화하는 정도로 진행했습니다. 그래서 저는 LS님꺼와 IY님꺼를 같이 진행했습니다.
팀 협업 방식
Notion과 구글 스프레드시트
기본적으로 팀 업무는 노션을 활용했습니다. 우리 팀 최고의 회의록 장인 IY님께서 회의록과 일정을 항상 체크해주셨습니다. 구글 스프레드 시트도 처음엔 제가 조금 쓰다가 IY님이 관리해주셨습니다. 쵝오!
팀 아카이브로 오픈 소스 관련한 링크를 모아두고, 정리노트로 지표와 데이터 컬럼에 대한 설명을 공부했습니다. 그리고 실험노트로 모델 학습 결과나 제출 결과를 기록했습니다. 스스로 부족한 점을 꼽자면.. 실험노트를 제대로 안 쓴거 같아 팀원들에게 미안했습니다. 핳핳..


Github
- Team github: github.com/ModuWay/baseline
전반적인 팀 업무에 필요한 문서 작업적인 부분은 노션에서 이뤄졌지만, 코드 공유는 Github을 통해 이뤄졌습니다. 이번에 Github으로 처음 팀 업무를 했는데 collaborator로서 아주 큰.. 잘못들을 commit으로 저질러서 팀장님의 마음을 .. 아프게했습니다. 핳핳 pull request하고 했어야했는데 사용규칙을 정해놓고 제대로 지키지 못해서 팀 repo를 좀.. 어지럽혔습니다. 이번에 경험한 시행착오가 이후에 스터디를 github으로 운영할 때 큰 도움이 됐습니다. clone -> add -> commit -> checkout -> push -> pull request -> merge -> pull -> add .. 반복!! 기억하자.. ㅎㅎㅎ
여기까지 보셨다면 잠시 Github을 가셔서 Star를 꾸욱..! 눌러주세요!! 미리 감사합니다 :)
제공 데이터
데이터 설명
- train_x_df.csv (10159560, 12)임의의 시점 부터 2020년 12월 31일까지 9가지 종류의 암호화폐의 분단위 가격정보를 가공한 데이터
- train_y_df.csv (883440, 12)임의의 시점 부터 2020년 12월 31일까지 9가지 종류의 암호화폐의 분단위 가격정보를 가공한 데이터
- test_x_df.csv (730020, 12)2021년 1월 1일 부터 임의의 시점까지 9가지 종류의 암호화폐의 분단위 가격정보를 가공한 데이터test_x_df속의 529가지 sample_id는 2021년 1월 1일 부터 임의의 시점까지 분단위 가격정보를 담고 있습니다.이 중 2021년 1월의 데이터로 public score를 계산하며, 2021년 2월의 데이터로 private score를 계산합니다.
- sample_submission.csv (529, 3)test_x_df에는 529가지 sample_id가 존재하고 각 sample_id는 1380분 동안의 가격 변동 정보를 포함합니다.
이 대회에서 가장 헷갈리는 점이 데이터에 대한 부분이었습니다. 보통의 데이터 경진대회에서는 train을 학습시키고, valid를 구분해 하이퍼 파라미터를 찾는 Cross Validation에 사용하고, test로 score를 냅니다. 하지만 이 대회는 제각각이었습니다(?) train은 train끼리 test도 test끼리 확인해줘야 했습니다. 이 부분이 가장 다루기 어려웠습니다. set마다 데이터가 가지는 특성이 차이가 있었기 때문이고, 이를 validation을 할 수 없다는 것도 큰 어려움 중 하나였습니다. 이미지 데이터가 그리워지는 점이었고, prediction과 forcasting의 차이를 여실히 느낄 수 있었습니다.
데이터 컬럼
- sample_id : 개별 샘플의 인덱스
- time : x_df는 0분 ~ 1379분, y_df는 0분 ~ 119분의 값을 갖습니다. 동일한 샘플 내 시간 정보
- coin_index : 10가지 종류의 코인에 대한 비식별화 인덱스 (0 ~9)
- open : open price
- high : high price
- low : low price
- close : close price
- volume : 거래량
- quote_av : quote asset volume
- trades : 거래 건 수
- tb_base_av : taker buy base asset volume
- tb_quote_av : taker buy quote asset volume
컬럼 12개 중에 1~3은 공부해볼 필요는 없었습니다. 하지만 주식을 겉햝기식으로 알고 있었기 때문에 4번 컬럼인 open(시가)부터는 공부가 좀 필요했습니다. investing 관련 사이트와 비트나인이라는 사이트를 주로 참고해서 각 컬럼들이 무슨 의미를 가지는지 활용 가치가 있는 컬럼은 무엇인지 판단했습니다. 대회에서는 open(시가)를 기준으로 결과값을 내게 되어있으나 고점/저점을 더 잘 나타내거나 어떤 매도법을 사용할지는 다른 컬럼과 관련된 지표를 활용할 수 있습니다.
What Is Volume of Trade?
Volume of trade is the total quantity of shares or contracts traded for a specified security. It can be measured on any type of security traded during a trading day. Volume of trade or trade volume is measured on stocks, bonds, options contracts, futures contracts, and all types of commodities.
https://www.investopedia.com/terms/v/volumeoftrade.asp
단순히 주식이 돈의 흐름이라고 가격만 중요하다고 생각할 수 있습니다. 하지만, 거래량 또한 중요한 지표가 될 수 있습니다. 뭔가 거래가 많은데 상향 그래프를 띈다면 더 오를 가능성이 높을 것이다처럼 마치 단순히 시장 가격이 형성될 때 수요와 공급에 포함되는 여러 요인들이 활용되듯이 주식 가격도 마찬가지이기 때문입니다.
제공된 데이터에 전처리된 부분
- sample id, coin index, time 세가지 컬럼을 제외하고 나머지 컬럼은 비식별화와 매수 시점에서 등락을 판단하기 위해 time=1379일때의 open(시가)를 기준으로 나눠져있습니다.
- 각 sample id별로 학습을 진행하기 위해 제공된 dataframe은 베이스라인에서 3차원 array로 가공됩니다.
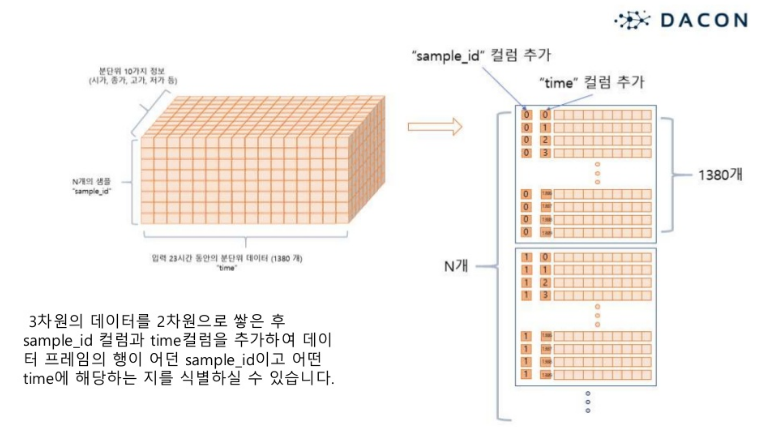
해당 부분은 베이스라인에 아래와 같이 코드가 제공됐습니다. 이번 시즌에서는 시도해보지 못 했지만, 다음 시즌2에서는 역으로 array to dataframe을 만들어서 test에 대한 매수매도 기록도 확인해볼 수 있도록 하고 싶습니다. 이번 대회 참여를 바탕으로 트레이딩 자동화를 만들어서 배포하고 싶은 작은 소망이 생겼습니다.
def df2d_to_array3d(df_2d):
# 입력 받은 2차원 데이터 프레임을 3차원 numpy array로 변경하는 함수
feature_size = df_2d.iloc[:,2:].shape[1]
time_size = len(df_2d.time.value_counts())
sample_size = len(df_2d.sample_id.value_counts())
array_3d = df_2d.iloc[:,2:].values.reshape([sample_size, time_size, feature_size])
return array_3d
데이터 사용규칙

- 위에 그림처럼 각 sample id간에는 같이 학습된 모델을 사용할 수 없습니다. 즉, 한 sample id가 하나의 데이터셋이 됩니다.
- 각 시점에서 매수/매도의 기준이 되는 가격은 open가를 기준으로 합니다.
처음에 사람들이 엄청 헷갈려했던 부분입니다. 이 부분은 코드 공유나 토론에서 나온 부분인데, sample_id는 서로 간에 학습에 영향을 미치면 안되니까 coin index나 다른 요소들을 분석해서 모델을 케이스별로 다르게 적용해보는 아이디어가 있었습니다. 전체적으로 확인해보느라 이 부분도 적용하지 못 했습니다. 시각화 해볼 때 전체를 다 띄워봤는데 데이터마다 계절성이나 추세가 비슷한 코인이 보이지 않아서 이 부분은 다시 데이터 하나씩 시각화를 통해 확인해봤지만, 너무 랜덤하고 흐름이 없어 난관이 예상됐습니다.
베이스라인
ARIMA
ARIMA를 auto_arima를 활용해 최적인 모수를 찾았는데 허점들이 좀 있었습니다. 일단 해당 패키지가 패키지 관리점수가 100점 만점에 60점 주변인 .. 성능이 좋지 않았는데 어떻게든 편하게 해보려다 모수를 적절하게 찾아내지 못 했습니다. 이후 앙상블 할때에도 돌아가는 모수로 전체 sample을 적용했는데 이 부분은 auto_arima의 argument 부분을 수정해줌으로써 해결했습니다.
Fbprophet
해당 모델을 이해하기까지 시간이 좀 걸렸습니다. 새롭게 써보는 모델이었기 때문에 fbprophet이 가지는 argument들은 어떤 특징을 고려하는지 테스트해보면서 진행했습니다.
RNN
RNN으로 적용은 해봤지만 제출하진 않았습니다. ARIMA나 Fbprophet 같은 통계적 모델에 비해 딥러닝 모델이라 그런지 예측 결과가 너무 달랐습니다. 코드 공유나 토론에서도 슬라이싱이나 윈도우로 슬라이딩을 해줘도 그렇게 성능 개선이 없었다는 글을 보고 베이스라인을 Ensemble해보는 방식으로 진행했습니다. => 이후 shake it shake it의 원인이 되어버렸습니다..
제출 코드
인공지능 비트 트레이더 경진대회 시즌 2
출처 : DACON - Data Science Competition
dacon.io
최종적으로는 Fbprophet과 ARIMA를 ensemble한 코드를 제출했습니다. 높은 순위였던 팀과 모수만 다른 것을 보고 조금 허무했습니다. ㅁㅅ차이!, 그리고 해당 주제는 시즌3를 마무리로 하고 연간 데이콘이지만 조기 종료하게 됐습니다. 이유는 Public과 Private간 score 차이가 너무 크고, 예를 들어 1월 데이터로 2월을 잘 예측하는 모델이더라도, 2월 데이터를 넣으면 예측을 잘 해내지 못하는 경우가 많았기 때문입니다. 주최측의 현명한 판단이라고 생각합니다.. :) 또륵..
Public score

Private score

최종적인 결과에서 순위가 크게 바뀌었습니다. Subway 30cm의 꿈은 4월엔 못 이뤘지만, 5월엔 꼭 이루고 싶습니다.. => 시즌2에 NeuralProphet을 사용하여 서브웨이 먹기에는 성공했습니다! 다만 팀 병합시기를 놓쳤기 때문에, MJ님이 개인 수상하셔서 서브웨이를 사주십니다 최고의 팀장 :)
제출 코드 기준 최종 순위
안타깝게도 한 팀을 앞에 두고 최종 순위권 안에 들지 못 했습니다..
